{kind=link}
{kind=link}
 This picture is showing a small sample of a possible Hilbert matrix.
The non-zero elements are shown as black pixels (v2.33 Feb2008 kago36z14j2).
This picture is showing a small sample of a possible Hilbert matrix.
The non-zero elements are shown as black pixels (v2.33 Feb2008 kago36z14j2).
SPINPACK is a big program package to compute
lowest eigenvalues and eigenstates and various expectation values
(spin correlations etc) for quantum
spin systems.
These model systems can for example describe magnetic properties of
insulators at very low temperatures (T=0) where the magnetic moments
of the particles form entangled quantum states.
The package generates the symmetrized configuration vector,
the sparse matrix representing the quantum interactions and
computes its eigenvalues and eigenvectors using iterative Matrix-Vector
multiplications (SpMV) as the compute intense core operation
and finaly some expectation values for the quantum system.
The first SPINPACK version was based on Nishimori's
TITPACK (Lanczos method, no symmetries), but
it was early converted to C/C++ and completely rewritten (1994/1995).
Other diagonalization algorithms are implemented too
(Lanzcos, 2x2-diagonalization and LAPACK/BLAS for smaller systems).
It is able to handle
Heisenberg,
t-J, and Hubbard-systems up to 64 sites or more using
special compiler and CPU features (usually up to 128)
or more sites in slower emulation mode (C++/CXX required for int128 emulation).
For instance we got the lowest eigenstates for the
Heisenberg Hamiltonian on a 40 site square lattice on our machines at 2002.
Note that the resources needed for computation grow exponentially with the
number of lattice sites (N=40 means 2^N/symfactor matrix dimension).
The Hamilton matrix can be stored to memory or file storage.
If there is no storage space the matrix elements will be recomputed
on every iteration round (slow).
The package is written mainly in C to get it running on all unix systems.
C++ is only needed for complex eigenvectors and
twisted boundary conditions if C has no complex extension like gcc has.
This way the package is very portable.
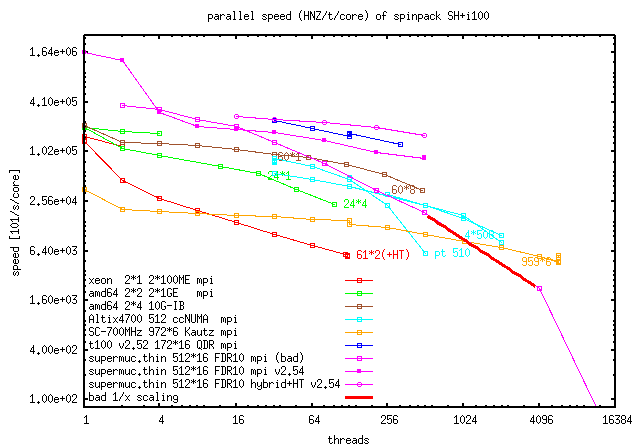
Parallelization can be done using MPI- and PTHREAD-library.
Mixed mode (hybrid mode) is possible, but not always faster
than pure MPI (2015).
v2.60 has slightly hybrid mode advantage on CPUs supporting hyper-threading.
This will hopefully be improved further. MPI-scaling is tested to work
up to 6000 cores, PTHREAD-scaling up to 510 cores but requires
careful tuning (scaling 2008-1016).
The program can use all topological symmetries,
S(z) symmetry and spin inversion to reduce matrix size.
This will reduce the needed computing recources by a linear factor.
Since 2015/2016 CPU vector extensions (SIMD, SSE2, AVX2)
are supported to get better performance for
the symmetry operations on bit representations of the quantum spins.
The results are very reliable because the package has been used
since 1995 in scientific work. Low-latency High-bandwith network
and low latency memory is needed to get best performance on large scale
clusters.
Verify download using:
gpg --verify spinpack.tgz.asc spinpack.tgz
The documentation is available in the doc-path.
Most parts of the documentation are rewritten in english now. If you
still find some parts written in german or out-of-date documentation
send me an email with a short hint where I find this part and
I want to rewrite this part as soon as I can.
Please see doc/history.html for latest changes.
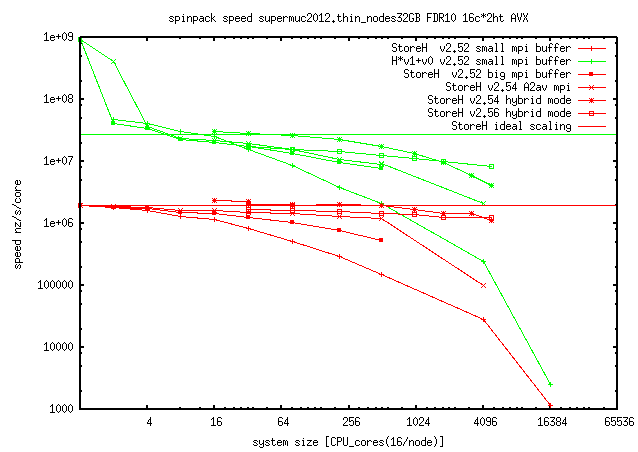
You can find a documentation about speed in the package or an older version
on this
spinpack-speed-page.
1) Effectiveness (energy consumption) of code is not optimal (2019-04).
Storing Matrix to memory is the
most effective method (much less energy and time).
Computing the Matrix is CPU-bounded (approx nzx*2000 Ops / 8 Byte)
and well optimized for Heisenberg-systems.
The butterfly network O(2logN) is used for bit permutation
to compute lattice symmetries (typical 4*N).
There is some room for hardware/software acceleration there.
But the core routine during iteration (SpMV) is network-I/O-bounded.
Ideal we have a FLOP to transfer rate of 2 FLOP per 8 Byte (double)
as worst case to 8 FLOP per 8 Byte (single-precision-complex)
as best case, which is
low compared to todays HPC-systems with 150 FLOP per Byte.
So about 1 percent of peak performance can be used on
QDR-Infiniband clusters only.
But at the moment (2019-04) index 4 Byte data and matrix size data
(latency) is transferred too which cost about 50%
more data. This must be changed before making the code using
full overlaping communication and using remaining CPU power for
data compression to get further acceleration on HPC-Clusters.
2) Parallel computation of two ore more datasets (vectors) at the same time
will increase memory consumption by a factor of (nnz+(m*2))/(nnz+2),
but makes memory bounded SpMV-core to more effective SpMM-core
(m times FLOPs per (factor above slightly increased) memory bandwith).
This is useful together with improved overlapping computation and
communication.
3) The most time consuming important function is b_smallest
in hilbert.c for matrix generation.
This function computes the representator
of a set of symmetric spin configurations (bit pattern) from a member of
this set. It also returns a phase factor and the orbit length.
It would be a great progress,
if the performance of that function could be improved. Ideas are welcome.
One of my ideas is to use FPGAs but my impression
on 2009 was, that the FPGA/VHDL-Compiler and Xilings-tools are so slow,
badly scaling and buggy, that code generation and debugging is really no
fun and a much better FPGA toolchain is needed for HPC.
2015-05 I added software benes-network to get gain of AVX2, but it looks like
that its still not the maximum available speed (HT shows near 2 factor,
bitmask falls out of L1-cache?).
Please use these data for your work or verify my data. Questions and corrections are welcome. If you miss data or explanations here, please send a note to me.
This picture is showing a small sample of a possible Hilbert matrix.
The non-zero elements are shown as black pixels (v2.33 Feb2008 kago36z14j2).
 This picture is showing a small sample of a possible Hilbert matrix.
The non-zero elements are shown as black (J1) and gray (J2) pixels
(v2.42 Nov2011 j1j2-chain N=18 Sz=0 k=0). Config space is sorted by
J1-Ising-model-Energy to show structures of the matrix.
Ising energy ranges are shown as slightly grayed arrays.
This picture is showing a small sample of a possible Hilbert matrix.
The non-zero elements are shown as black (J1) and gray (J2) pixels
(v2.42 Nov2011 j1j2-chain N=18 Sz=0 k=0). Config space is sorted by
J1-Ising-model-Energy to show structures of the matrix.
Ising energy ranges are shown as slightly grayed arrays.
. . .
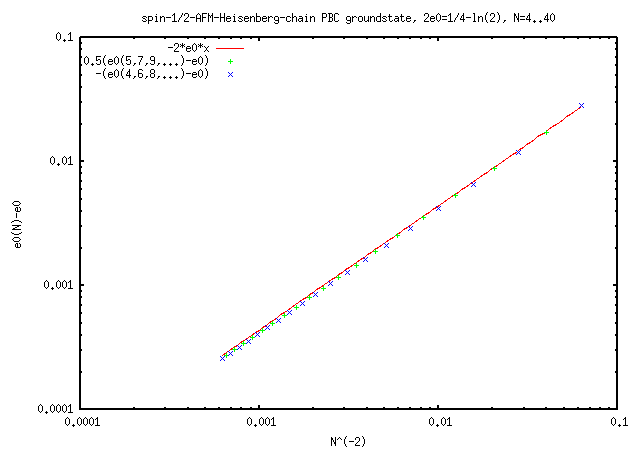 Ground state energy scaling for finite size spin=1/2-AFM-chains N=4..40
using up to 300GB memory to store the N=39 sparse matrix and 245 CPU-houres
(2011, src=lc.gpl).
Ground state energy scaling for finite size spin=1/2-AFM-chains N=4..40
using up to 300GB memory to store the N=39 sparse matrix and 245 CPU-houres
(2011, src=lc.gpl).