URZ Compute-Server Meggie
|
|
 |
Meggie -- 8 Wege QuadOpteron-System
Aktuelles:
-
Jul2013 - gcc-4.8.1 + 4.6.3 (incl. gmp,mpfr,mpc,isl fuer c,c++,fortran) installiert
|
Rechnersystem-Kurzbeschreibung
Mit der Installation des Opteron-Systems der Firma Megware im Januar 2009 steht
den Nutzern unserer Universität ein Mehrprozessor-Hochleistungsrechner
mit Parallelisierungsmöglichkeit (SMP) zur Verfügung.
Die Meggie ist für spezielle Anwendungen mit hohen Anforderungen
an Compute-Leistungen oder für Software, die nur auf x86 Plattformen
läuft, bestimmt. Sie löst die älteren SMP Systeme ab.
Hardware
| Architektur: | SMP, cache-coherent Non-Uniform Memory Architecture (ccNUMA) |
| Prozessor (CPU): | 8 x QuadOpteron 8378 - 2411MHz, L1=2*64KB (6.4GB/s 1.3ns), L2=512KB | |
| Board: | Tyan.com Thunder n4250QE S4985G3NR-E |
| Hauptspeicher (RAM): | 256 Gbytes (4*8GB-DDR2/4coreCPU, nVidia CK804 Memory Controller, 2015-07 -16GB defekt) |
| Festplatten (HD): | 2x320 GBytes (82MB/s, RAID0=161MB/s), Mai2012: +6x1TB SoftRAID0 (1.8TB,280MB/s + 3.6TB,550MB/s) |
| Netzwerkanschluss: | 2xEthernet, 1Gbit/s |
| Stromverbrauch: | ca. 1600W, (3+1) Netzteile |
| Performance-Daten: | MemStream single=770MB/s, sum=14.7GB/s
|
| | MemLatency 200ns(4MB)..580ns(1GB)
|
| | 32*MPI_sendrecv 4GB/s
|
| | Peak = 308 GFLOPs (0.83GB/GFLOP)
|
Systemsoftware, Kommerzielle Software
- CentOS-5.6
- Fortran, C/C++ gcc-4.1.2 (+4.8.1), oprofile-0.9.4, kvm, qemu-1.4.1
- Fluent/Gambit (FVST/ISUT)
- ANSYS 11-14 (ansys_start)
Hinweise)
- OpenFOAM-2.2
- Matlab 2009b-2013a (incl. java), bitte qsub -I -X -N matlab ... nutzen
- Maxima 5.23.2 (aehnlich Mathematica/Maple)
- ACHTUNG: Programme mit Floating-Lizenzen koennen im Jobsystem ggf. erfolglos abbrechen,
da zum Ausfuehrungszeitpunkt wegen des Campusweiten Lizenz-Sharings
keine verfuegbaren Lizenzen garantiert werden koennen.
- Jobsystem: Torque
- Kurzbeschreibung jobfile job.sh
#!/bin/bash
# Bitte benoetigte Resourcen ppn, walltime und mem unbedingt nach unten anpassen!
# ppn=Anzahl_CPUs(1..30), walltime=absolute-CPU-time hh:mm:ss, mem=SumMemory(max.240gb)
# vmem=mem (no swap is available for computations)
# output nach job.sh.oNNN
# start: qsub job.sh
#
#PBS -l nodes=1:ppn=18,ncpus=18
##PBS -l nodes=1:ppn=28,ncpus=28
#PBS -l walltime=24:00:00,mem=64gb,vmem=64gb
##PBS -l walltime=24:00:00,mem=215gb,vmem=215gb
#PBS -m n
#PBS -j oe
cd $PBS_O_WORKDIR
mpi-selector --query # debugging, show mpi environment
# gewuenschte MPI-CPU-Zahl ermitteln:
NP=$(cat $PBS_NODEFILE | wc -l)
echo "DEBUG: JOBID=$PBS_JOBID NP=$NP WORKDIR=$PBS_O_WORKDIR"
# default ulimit -v settings (=vmem) may not be usefull for ppn>1
OVMEM=$(ulimit -v)
NVMEM=$(( $OVMEM / $NP ))
echo "DEBUG: NVMEM= $OVMEM / $NP = $NVMEM"
ulimit -v $NVMEM # 4GB per process (but 18*4gb=72gb will hit 64gb)
#OMP_NUM_THREADS=1 # use this for mpi-programs with 1 thread per task
OMP_NUM_THREADS=$NP # set number of CPU-cores for OpenMP programs
#
echo "DEBUG: OMP_NUM_THREADS=$OMP_NUM_THREADS" # easier to debug
#
# naechste Zeile fuer Single-Job ausommentieren
#./a.out # single Job starten (ncpus=1)
#
# naechste Zeile fuer ANSYS-Batch-Job auskommentieren (ungetestet)
#/opt/ansys_inc/v130/ansys/bin/ansys130 -b -np $NP -i test.dat -o test.out
#
# naechste Zeile fuer MPI-Job auskommentieren
#mpiexec -np $NP ./a.out # mpi-job starten (ppn=ncpus=2...30)
#
/usr/local/bin/qstat -f $PBS_JOBID
- Kurzbeschreibung Job-Kommandos
qsub job.sh # Job abschicken (man qsub)
# output buffer in /var/spool/torque/spool/*
pbstop # top-Anzeige fuer Jobs
qstat -s # Jobliste anzeigen (man qstat)
qdel JOBNUMMER # Job loeschen (man qdel)
qmgr -c 'p s' # Queues und Konfigurationen anzeigen
- Checkpointed und abgebrochene Jobs weiterrechnen
# Einstellung einer Jobkette fuer Langlaeufer mit Checkpointing
# "depend" verhindert vorzeitigen Start eines FolgeJobs zum weiterrechnen
qsub ... longrunJob # JobId=9012 4h + kill
qsub ... -W depend=afternotok:9012 longrunJob # JobId=9013 +4h
qsub ... -W depend=afternotok:9013 longrunJob # JobId=9014 +4h etc.
Kurzbeschreibung interaktive Jobs (z.B: fluent)
# interaktiver fluent-Job mit 4 CPUs, max. 4GB/Job, max. 8h
qsub -I -X -V -l nodes=1:ppn=4,ncpus=4,walltime=8:00:00,mem=4gb,vmem=4gb -N fluent
# je nach Anwendung CPU-Zahl begrenzen (z.B. export OMP_NUM_THREADS=4)
# dann fluent starten und mit ^D oder exit verlassen
Zugang/Ansprechpartner
Der Zugang erfolgt aus der UNI-Domain über
ssh
meggie.urz.uni-magdeburg.de (141.44.8.33).
Der Zugang erfolgt passwortlos mit ssh-public-keys.
Wenn Sie Windows und Excced für den Zugang (grafisch) benutzen,
beachten Sie bitte die Konfigurationshinweise des URZ.
Accounts können im
Kontaktbüro
des Rechenzentrums beantragt werden.
Bitte beachten Sie, dass unsere Computeserver nicht der Aufbewahrung von Daten
dienen. Deshalb sind die Plattensysteme nur teilweise mit Redundanz
ausgestattet und auf Backups wird zugunsten von Performance und Stabilitaet
verzichtet.
Sichern Sie bitte selbst Ihre Resultate zeitnah und entfernen Sie angelegte
Dateien, um anderen Nutzern genug Speicher fuer deren Rechnungen zur Verfuegung
stellen zu koennen. Danke!
Für Fragen und Probleme wenden Sie sich bitte an
mailto:Joerg.Schulenburg(at)URZ.Uni-Magdeburg.DE?subject=WWW-Meggie
oder Tel.58408.
Termine/Infos/Planung:
20.01.09 - Inbetriebnahme Meggie
11.02.09 - Installation Fluent-lnamd64-2.3.16 + EDEM
17.02.09 - ca. 10:30 Stromausfall bei Elektroarbeiten
25.02.09 - ca. 15:30 Out of memory crash
08.03.09 - ca. 23:02 Out of memory crash (Massnahme: ssh-login mit nice)
24.03.09 - interaktive graphische Jobs nun moeglich (qsub -V -I -X ...)
21.06.09 - ca. 09:30 Out of memory crash (Massnahme: pbs_mom mit nice)
19.08.09 - ca. 16:45 Power Off (Ursache in Untersuchung)
22.08.09 - 06:00 Ausfall Klimaanlage (bis Montag)
28.08.09 - ca. 08:35 Out of memory crash
19.10.09 - ca. 16:30 Power Off by Out of memory crash (set resources_max.mem=250gb, resources_default.mem = 8gb)
04.11.09 - matlab2009b + java-1.6.0 installiert (start via qsub -V -I -X -N matlab ...)
29.11.09 - 17:00 Ausfall Klimaanlage (bis Montag)
11.12.09 - ansys-12 + fluent-12 (fuer edem-2.2) installiert
18.12.09 - zombiekiller-script installiert (killt per Crontab Prozesse mit verlorenen stdin/stdout, meist fluent)
23.12.09 - pam-limits gesetzt (bitte nicht nohup, sondern Job-system nutzen!)
04.01.10 - hoeherer Nice-Level fuer Torque-Jobs eingestellt
13.01.10 - 18:00 Ausfall Klimaanlage (Wasser-Rueckkuehlung)
14.03.10 - 16:00 Out of memory crash (set resources_max.vmem=250gb, neues jobscript)
... hilft aber nicht bei Paralleljobs! Kennt jemand eine Loesung?
... z.B. ulimit-v/NP vom Nutzer
17.06.10 - 21:00 Ausfall Klimaanlage (Notabschaltung)
30.06.10 - crash (unknown reason, OOM=Out_Of_Memory ?)
02.07.10 - crash (unknown reason, OOM?, enhanced logging started)
22.09.10 - crash (OOM, parallel job ohne ulimit-v/NP als Verursacher)
17.04.11 - crash OOM
28.04.11 - crash, Update to CentOS-5.6 + k2.6.18-238 + oom_adj=15 still crashes on OOM
set server resources_max.vmem=240gb, user-crontab disabled
bitte mpi-Jobs neu compilieren und im Jobscript Option ncpus zufuegen!
27.05.11 - ab 14:00 Abschaltung wegen Arbeiten an der Klimaanlage (bis max. Montag)
10.06.11 - 14:45 new queue q1 created for single cpu-jobs (max. 4)
21.06.11 - Ansys-13 installed (ansys_workbench)
07.07.11 - System gegen OOM gehaertet (overcommit_memory=2, see below)
27.02.12 - uptime 275 days (no OOM crashs anymore)
13.03.12 - Anpassungen der Queues (max_user_queuable)
29.03.12 - weitere Queue-Anpassungen und Nutzerbeschraenkungen (auch zukuenftig)
bitte statt vielen Singlejobs, einzelne Multitaskjobs nutzen
bash-script: for x in $(seq $NP);do(do_task$x)&done;wait
uptime 306 days
09.05.12 - queue batch: max.walltime von 480 auf 100h reduziert, um Warteiten
zwischen Nutzerjobs zu reduzieren
21.05.12 - reboot zur Disk-Erkennung, 359 days uptime
25.05.12 - /scratch2/tmp erstellt (1.8TB 280MB/s, 2 disks, see /proc/mdstat)
- /scratch3/tmp erstellt (3.6TB 550MB/s, 4 disks)
28.08.12 - Klimaausfall 3h nach Spannungsdrop 03:43 bis max Tn+29C ohne Ausfall
27.01.13 - sata5 wegen defekten Sektoren ausgefallen, /scratch3 defekt
07.04.13 - /scratch3 temporaer rekonfiguriert 3+0RADID0 2.7TB, 385MB/s
09.07.13 - /usr/local/bin/gcc 4.8.1 (c,c++,fortran) compiliert
10.07.13 - /usr/gcc-4.6.3/bin/gcc 4.6.3 (c,c++,fortran) compiliert
06.09.13 - ansys14 + SP 14.51 installiert
28.11.13 - matlab2013a installiert (matlab2013b nicht auf OS installierbar)
23.01.14 - OpenFoam2.2 installiert in /opt/OpenFOAM22/OpenFOAM/OpenFOAM-2.2.x/
05.02.14 - reboot um kvm zu aktivieren (evl. update CentOS geplant, ca 1d)
15.05.14 - maxima 5.23.2 (OS-Ersatz fuer mathematica/maple) installiert
05.03.15 22:50 - spontan off (ipmi meldet power failure, aber 4 Netzteile intakt)
06.03.15 15:50 - spontan off (ipmi meldet power failure, aber 4 Netzteile intakt)
- Belastungstests ohne Ausfall
19.03.15 spontan off bei start OpenFoam-Benchmark (einmalig)
29.06.15 20:06 - 14 reboots in 21-27min-Takt
30.06.15 09:35 - 3 reboots im 5-6min-Takt
30.06.15 18:30 - spontan Ausfall (ipmi/ssh tot), bootet nicht mehr ins BIOS
- ipmi bei off erreichbar, Hardware-Problem? Betrieb: 6.5 Jahre
- CMOS-BAT CR2032 2.9V (test 3.42V ohne Erfolg)
- Betrieb ohne Expansion-Board (CPU4-7) moeglich
07.07.15 defekten 8GB-DIMM entfernt, 16GB Memory fehlen an CPU7, rest=240GB
02.05.17 slurm-16.05-installation (failed)
19.07.17 ldconfig-failure, glibc-conflicts, host down until 24.07.17
18.08.17 Stromausfall durch Selbsschutz-Abschaltung ueberhitzter USV,
Klimatisierung der USV durch zernagtes Stromkabel stillgelegt
12.01.18-17.01.18 some hours down time for maintenance
01.01.20 server disabled, special tasks only
Projekte:
- SpinPack
- Quantenspinsysteme, exakte Diagonalisierung
- CCCM
- Quantenspinsysteme, Coupled Cluster Method
- Simulationen von molekularen Strukturen auf Oberflächen von
Festkörpern und deren Eigenschaften (Struktur, Dynamik, Reaktivität),
Methoden: Quantenchemie-Codes wie
Car-Parinello molecular
dynamics/Dichtefunktionaltheorie für periodische Strukturen und
Dalton
(
Institut für Chemie (ICH), FVST, Uni Magdeburg, Aug 2009)
- Technische Dynamik (IFME)
- Assignment Problem
(
Kuhn Munkres Algorithm), FMB-ILM
(Dez2010)
- Arbeitsgruppe
"Computerorientierte Theoretische Physik" (Jobs mit 6-10GB Speicherbedarf, Maerz2011),
Projekt DLA
- Bild-Simulationen zu Rastertunnel- und Rasterkraftmikroskopie mit
Quantum-Expresso
der FVST - Institut fuer Chemie (ICH) Jul. 2011
- Eigenfrequenzen von Stroemungsmodellen, Realisierbarkeit phoXonischer Kristalle (Comsol.CFD Jun2012)
- 2D Simulation einer H-Darrieus-Wasserturbine mit OpenFoam, S. Hoerner (2014)
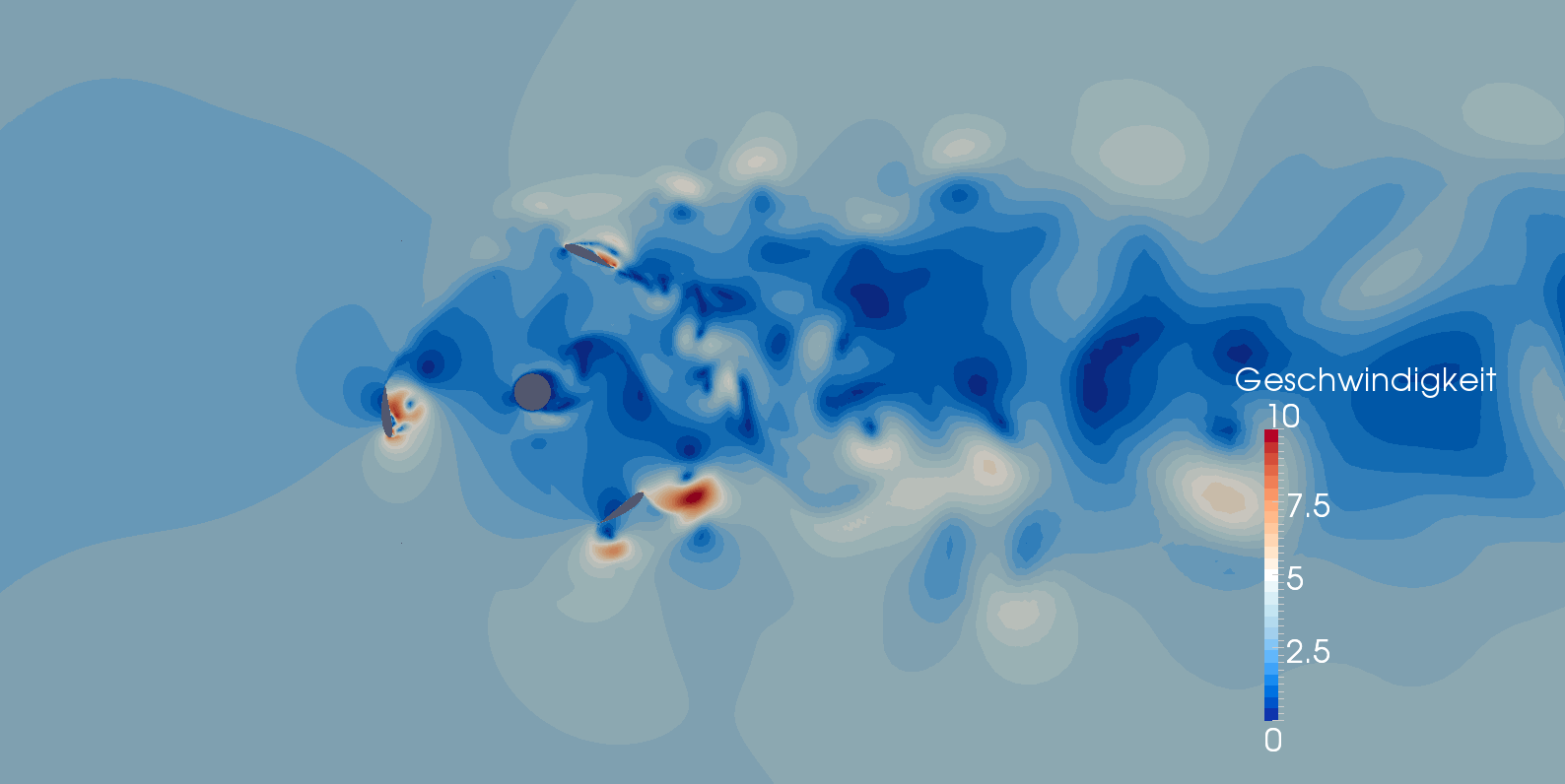 video
video
- Grosse Ansys FEM-Simulationen, Institut fuer Mikro- und Sensorsysteme (IMOS 2013, 2015)
- Pore network drying simulations (using matlab parallel, IVT_TVT 2014/2015)
Probleme:
...
Weitere HPC-Systeme:
IB-Cluster t100(2016),
HP GS 1280 marvel(2003-2009),
MPI-Cluster SC5832 kautz(2009)
weitere Infos zu
zentralen Compute-Servern im CMS
Author: Joerg Schulenburg, Uni-Magdeburg URZ, Tel. 58408 (2009-2012)